- Types of pipelines
- Configure a pipeline
- Visualize pipelines
- Pipelines API
CI/CD pipelines
Pipelines are the top-level component of continuous integration, delivery, and deployment.
Pipelines comprise:
- Jobs, which define what to do. For example, jobs that compile or test code.
- Stages, which define when to run the jobs. For example, stages that run tests after stages that compile the code.
Jobs are executed by runners. Multiple jobs in the same stage are executed in parallel, if there are enough concurrent runners.
If all jobs in a stage succeed, the pipeline moves on to the next stage.
If any job in a stage fails, the next stage is not (usually) executed and the pipeline ends early.
In general, pipelines are executed automatically and require no intervention once created. However, there are also times when you can manually interact with a pipeline.
A typical pipeline might consist of four stages, executed in the following order:
- A
buildstage, with a job calledcompile. - A
teststage, with two jobs calledtest1andtest2. - A
stagingstage, with a job calleddeploy-to-stage. - A
productionstage, with a job calleddeploy-to-prod.
Types of pipelines
Pipelines can be configured in many different ways:
- Basic pipelines run everything in each stage concurrently, followed by the next stage.
- Directed Acyclic Graph Pipeline (DAG) pipelines are based on relationships between jobs and can run more quickly than basic pipelines.
- Multi-project pipelines combine pipelines for different projects together.
- Parent-Child pipelines break down complex pipelines into one parent pipeline that can trigger multiple child sub-pipelines, which all run in the same project and with the same SHA.
- Pipelines for Merge Requests run for merge requests only (rather than for every commit).
- Pipelines for Merged Results are merge request pipelines that act as though the changes from the source branch have already been merged into the target branch.
- Merge Trains use pipelines for merged results to queue merges one after the other.
Configure a pipeline
Pipelines and their component jobs and stages are defined in the CI/CD pipeline configuration file for each project.
For a list of configuration options in the CI pipeline file, see the GitLab CI/CD Pipeline Configuration Reference.
You can also configure specific aspects of your pipelines through the GitLab UI. For example:
- Pipeline settings for each project.
- Pipeline schedules.
- Custom CI/CD variables.
Ref Specs for Runners
When a runner picks a pipeline job, GitLab provides that job’s metadata. This includes the Git refspecs, which indicate which ref (branch, tag, and so on) and commit (SHA1) are checked out from your project repository.
This table lists the refspecs injected for each pipeline type:
| Pipeline type | Refspecs |
|---|---|
| Pipeline for Branches |
+<sha>:refs/pipelines/<id> and +refs/heads/<name>:refs/remotes/origin/<name>
|
| pipeline for Tags |
+<sha>:refs/pipelines/<id> and +refs/tags/<name>:refs/tags/<name>
|
| Pipeline for Merge Requests | +<sha>:refs/pipelines/<id>
|
The refs refs/heads/<name> and refs/tags/<name> exist in your
project repository. GitLab generates the special ref refs/pipelines/<id> during a
running pipeline job. This ref can be created even after the associated branch or tag has been
deleted. It’s therefore useful in some features such as automatically stopping an environment,
and merge trains
that might run pipelines after branch deletion.
View pipelines
You can find the current and historical pipeline runs under your project’s CI/CD > Pipelines page. You can also access pipelines for a merge request by navigating to its Pipelines tab.
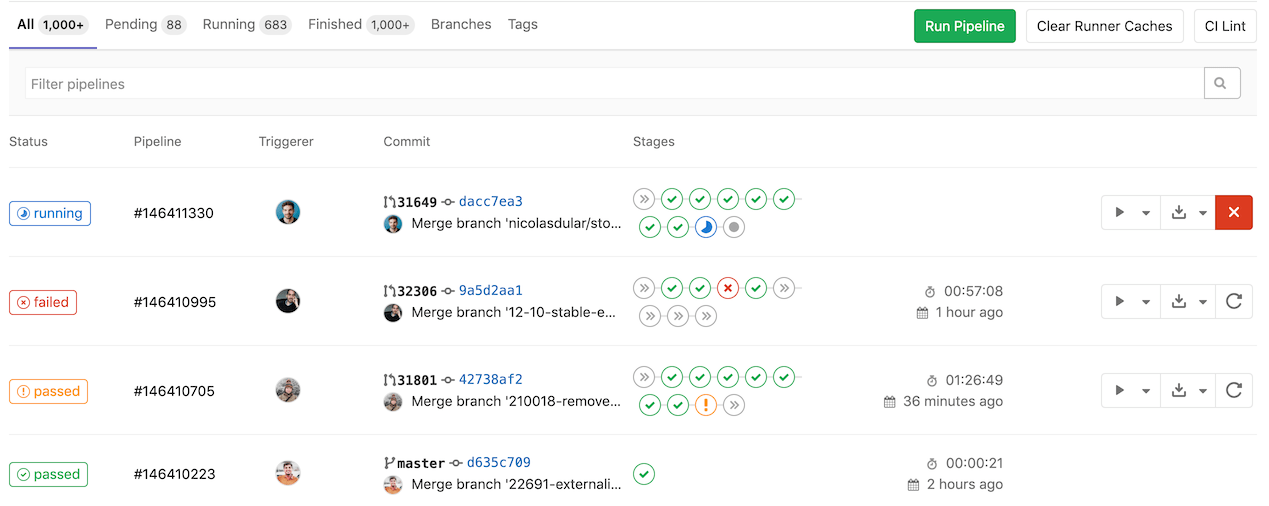
Click a pipeline to open the Pipeline Details page and show the jobs that were run for that pipeline. From here you can cancel a running pipeline, retry jobs on a failed pipeline, or delete a pipeline.
Starting in GitLab 12.3, a link to the
latest pipeline for the last commit of a given branch is available at /project/pipelines/[branch]/latest.
Also, /project/pipelines/latest redirects you to the latest pipeline for the last commit
on the project’s default branch.
Starting in GitLab 13.0, you can filter the pipeline list by:
- Trigger author
- Branch name
- Status (GitLab 13.1 and later)
- Tag (GitLab 13.1 and later)
Run a pipeline manually
Pipelines can be manually executed, with predefined or manually-specified variables.
You might do this if the results of a pipeline (for example, a code build) are required outside the normal operation of the pipeline.
To execute a pipeline manually:
- Navigate to your project’s CI/CD > Pipelines.
- Select the Run pipeline button.
- On the Run pipeline page:
- Select the branch or tag to run the pipeline for in the Run for branch name or tag field.
- Enter any environment variables required for the pipeline run. You can set specific variables to have their values prefilled in the form.
- Click the Run pipeline button.
The pipeline now executes the jobs as configured.
Prefill variables in manual pipelines
Introduced in GitLab 13.7.
You can use the value and description
keywords to define
pipeline-level (global) variables
that are prefilled when running a pipeline manually.
In pipelines triggered manually, the Run pipelines page displays all top-level variables
with a description and value defined in the .gitlab-ci.yml file. The values
can then be modified if needed, which overrides the value for that single pipeline run.
The description is displayed below the variable. It can be used to explain what the variable is used for, what the acceptable values are, and so on:
variables:
DEPLOY_ENVIRONMENT:
value: "staging" # Deploy to staging by default
description: "The deployment target. Change this variable to 'canary' or 'production' if needed."
You cannot set job-level variables to be pre-filled when you run a pipeline manually.
Run a pipeline by using a URL query string
Introduced in GitLab 12.5.
You can use a query string to pre-populate the Run Pipeline page. For example, the query string
.../pipelines/new?ref=my_branch&var[foo]=bar&file_var[file_foo]=file_bar pre-populates the
Run Pipeline page with:
-
Run for field:
my_branch. -
Variables section:
- Variable:
- Key:
foo - Value:
bar
- Key:
- File:
- Key:
file_foo - Value:
file_bar
- Key:
- Variable:
The format of the pipelines/new URL is:
.../pipelines/new?ref=<branch>&var[<variable_key>]=<value>&file_var[<file_key>]=<value>
The following parameters are supported:
-
ref: specify the branch to populate the Run for field with. -
var: specify aVariablevariable. -
file_var: specify aFilevariable.
For each var or file_var, a key and value are required.
Add manual interaction to your pipeline
Manual actions, configured using the when:manual keyword,
allow you to require manual interaction before moving forward in the pipeline.
You can do this straight from the pipeline graph. Just click the play button to execute that particular job.
For example, your pipeline might start automatically, but it requires manual action to
deploy to production. In the example below, the production
stage has a job with a manual action.

Start multiple manual actions in a stage
Introduced in GitLab 11.11.
Multiple manual actions in a single stage can be started at the same time using the “Play all manual” button. After you click this button, each individual manual action is triggered and refreshed to an updated status.
This functionality is only available:
- For users with at least Developer access.
- If the stage contains manual actions.
Delete a pipeline
Introduced in GitLab 12.7.
Users with the Owner role in a project can delete a pipeline by clicking on the pipeline in the CI/CD > Pipelines to get to the Pipeline Details page, then using the Delete button.

Pipeline quotas
Each user has a personal pipeline quota that tracks the usage of shared runners in all personal projects. Each group has a usage quota that tracks the usage of shared runners for all projects created within the group.
When a pipeline is triggered, regardless of who triggered it, the pipeline quota for the project owner’s namespace is used. In this case, the namespace can be the user or group that owns the project.
How pipeline duration is calculated
Total running time for a given pipeline excludes retries and pending (queued) time.
Each job is represented as a Period, which consists of:
-
Period#first(when the job started). -
Period#last(when the job finished).
A simple example is:
- A (1, 3)
- B (2, 4)
- C (6, 7)
In the example:
- A begins at 1 and ends at 3.
- B begins at 2 and ends at 4.
- C begins at 6 and ends at 7.
Visually, it can be viewed as:
0 1 2 3 4 5 6 7
AAAAAAA
BBBBBBB
CCCC
The union of A, B, and C is (1, 4) and (6, 7). Therefore, the total running time is:
(4 - 1) + (7 - 6) => 4
How pipeline quota usage is calculated
Pipeline quota usage is calculated as the sum of the duration of each individual job. This is slightly different to how pipeline duration is calculated. Pipeline quota usage doesn’t consider any overlap of jobs running in parallel.
For example, a pipeline consists of the following jobs:
- Job A takes 3 minutes.
- Job B takes 3 minutes.
- Job C takes 2 minutes.
The pipeline quota usage is the sum of each job’s duration. In this example, 8 runner minutes would be used, calculated as: 3 + 3 + 2.
Pipeline security on protected branches
A strict security model is enforced when pipelines are executed on protected branches.
The following actions are allowed on protected branches only if the user is allowed to merge or push on that specific branch:
- Run manual pipelines (using the Web UI or pipelines API).
- Run scheduled pipelines.
- Run pipelines using triggers.
- Run on-demand DAST scan.
- Trigger manual actions on existing pipelines.
- Retry or cancel existing jobs (using the Web UI or pipelines API).
Variables marked as protected are accessible only to jobs that run on protected branches, preventing untrusted users getting unintended access to sensitive information like deployment credentials and tokens.
Runners marked as protected can run jobs only on protected branches, preventing untrusted code from executing on the protected runner and preserving deployment keys and other credentials from being unintentionally accessed. In order to ensure that jobs intended to be executed on protected runners do not use regular runners, they must be tagged accordingly.
Visualize pipelines
Pipelines can be complex structures with many sequential and parallel jobs.
To make it easier to understand the flow of a pipeline, GitLab has pipeline graphs for viewing pipelines and their statuses.
Pipeline graphs can be displayed as a large graph or a miniature representation, depending on the page you access the graph from.
GitLab capitalizes the stages’ names in the pipeline graphs.
View full pipeline graph
- Visualization improvements introduced in GitLab 13.11.
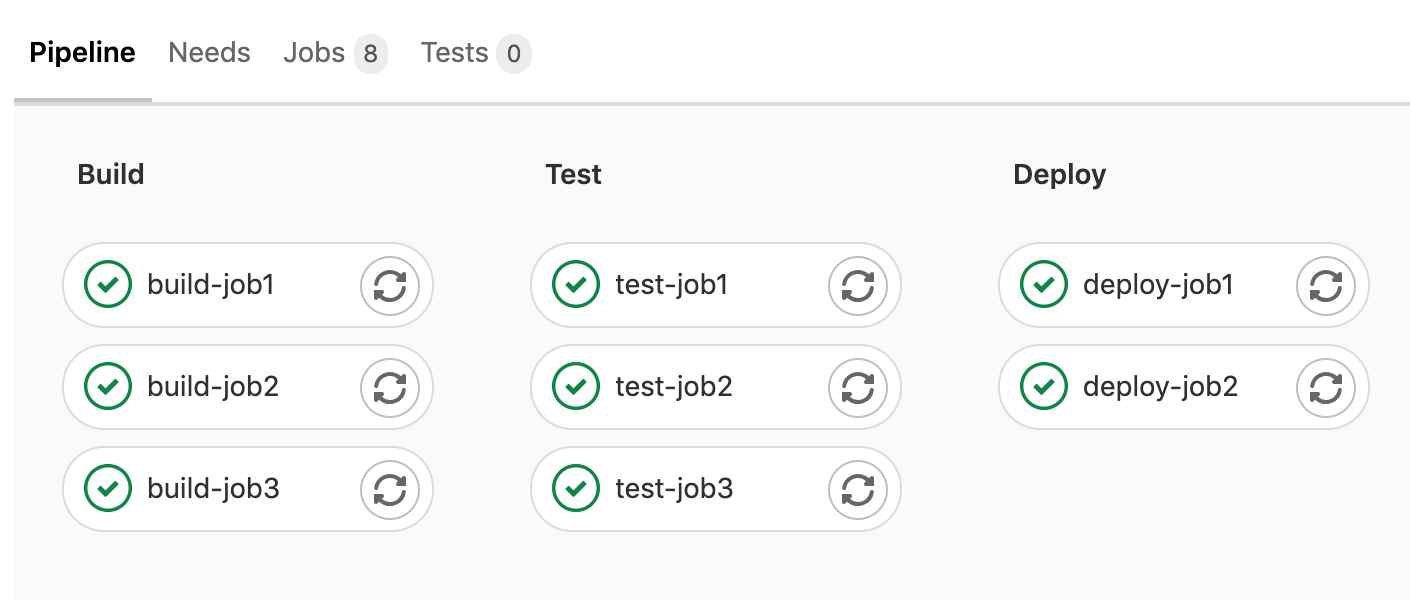
The pipeline details page displays the full pipeline graph of all the jobs in the pipeline.
You can group the jobs by:
-
Stage, which arranges jobs in the same stage together in the same column.
-
Job dependencies, which arranges jobs based on their
needsdependencies.
Multi-project pipeline graphs help you visualize the entire pipeline, including all cross-project inter-dependencies.
View job dependencies in the pipeline graph
- Introduced in GitLab 13.12.
- Deployed behind a feature flag, disabled by default.
- Enabled by default in GitLab 13.12.
- Enabled on GitLab.com.
- Recommended for production use.
- To disable in GitLab self-managed instances, ask a GitLab administrator to disable it.
This in-development feature might not be available for your use. There can be risks when enabling features still in development. Refer to this feature’s version history for more details.
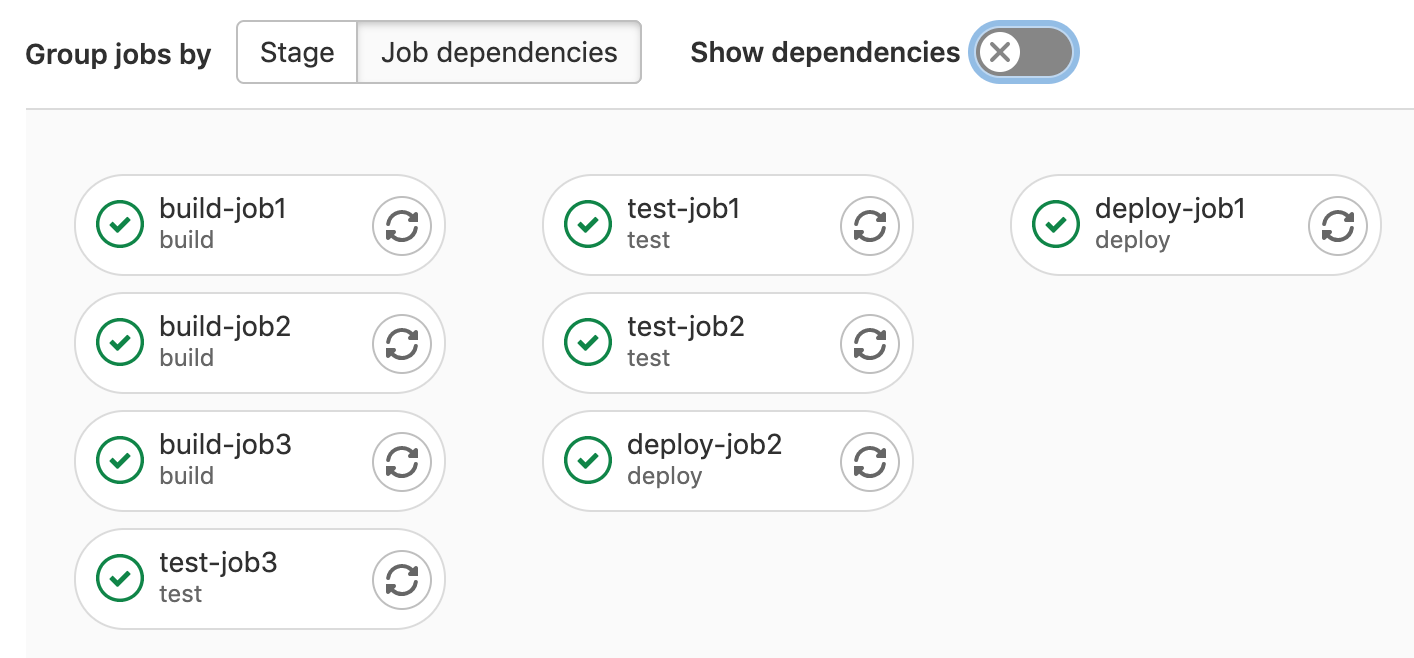
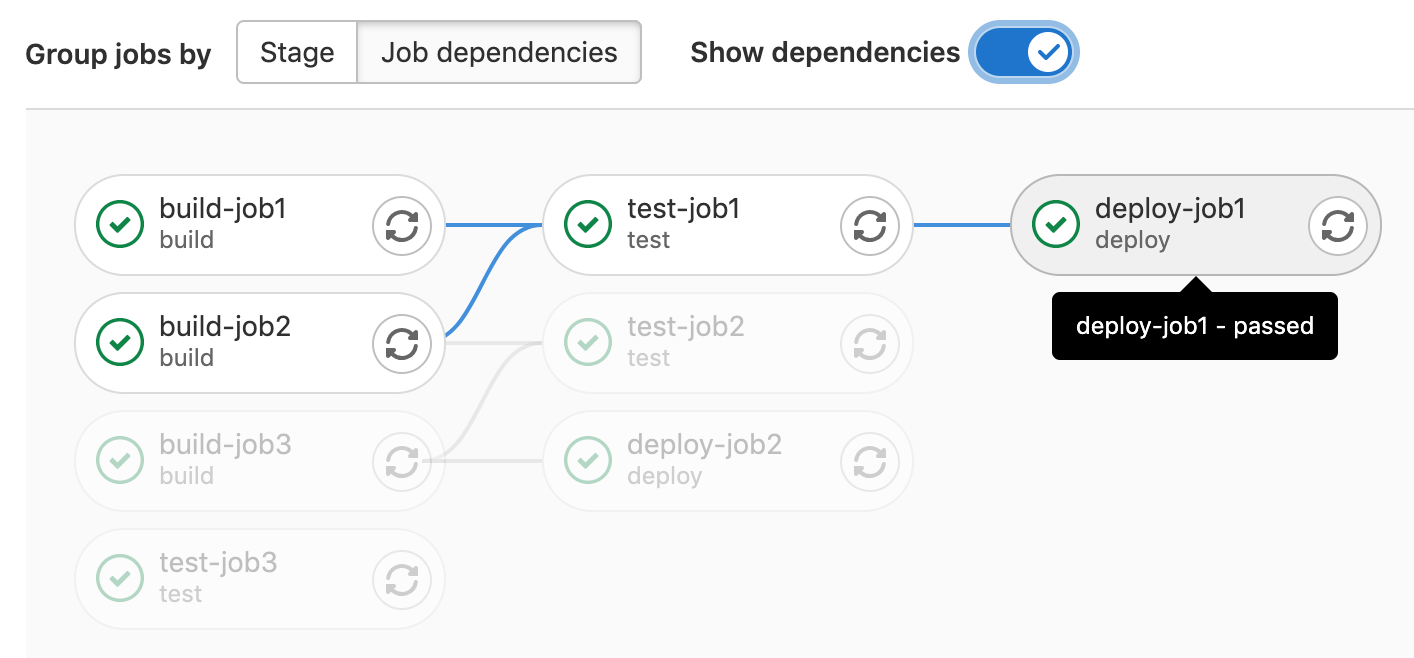
You can arrange jobs in the pipeline graph based on their needs
dependencies.
Jobs in the leftmost column run first, and jobs that depend on them are grouped in the next columns.
For example, build-job2 depends only on jobs in the first column, so it displays
in the second column from the left. deploy-job2 depends on jobs in both the first
and second column and displays in the third column:
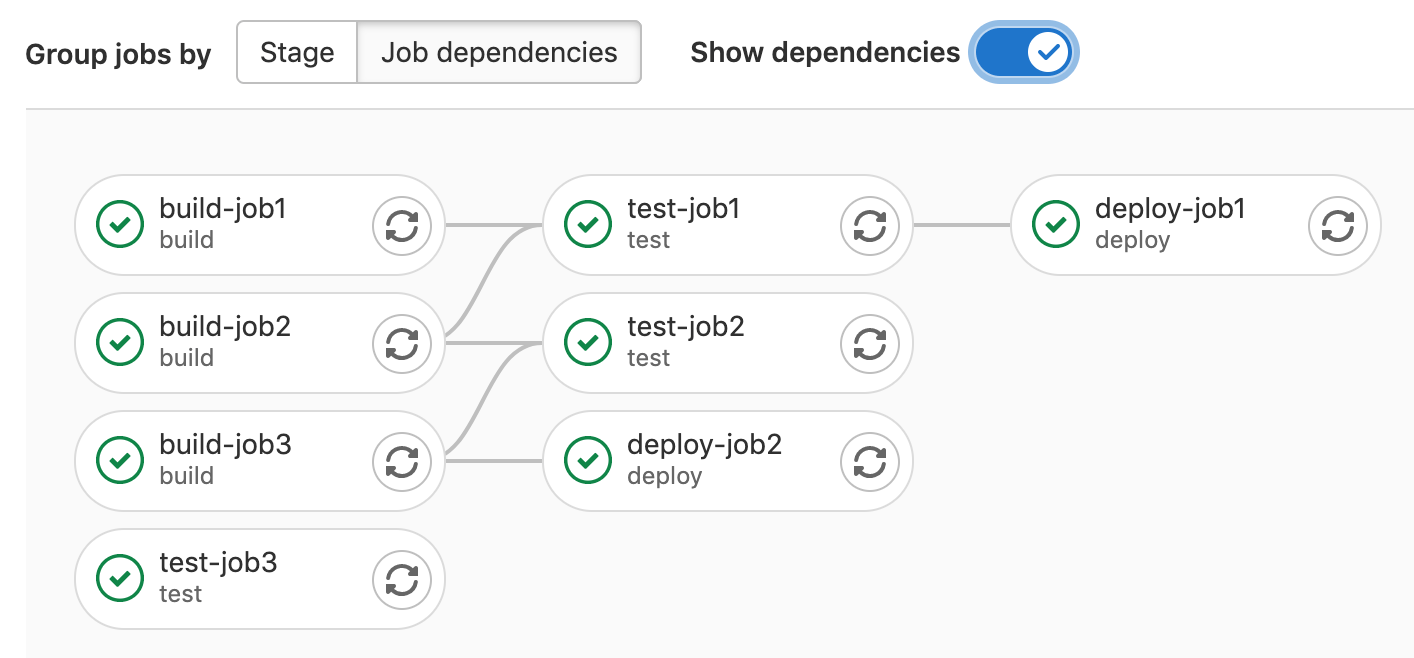
To add lines that show the needs relationships between jobs, select the Show dependencies toggle.
These lines are similar to the needs visualization:
To see the full needs dependency tree for a job, hover over it:
Enable or disable job dependency view
The job dependency view is deployed behind a feature flag that is enabled by default. GitLab administrators with access to the GitLab Rails console can disable it.
To enable it:
Feature.enable(:pipeline_graph_layers_view)
To disable it:
Feature.disable(:pipeline_graph_layers_view)
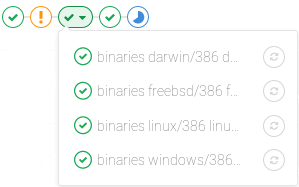
Pipeline mini graphs
Pipeline mini graphs take less space and can tell you at a quick glance if all jobs passed or something failed. The pipeline mini graph can be found when you navigate to:
- The pipelines index page.
- A single commit page.
- A merge request page.
Pipeline mini graphs allow you to see all related jobs for a single commit and the net result of each stage of your pipeline. This allows you to quickly see what failed and fix it.
Pipeline mini graphs only display jobs by stage.
Stages in pipeline mini graphs are collapsible. Hover your mouse over them and click to expand their jobs.
| Mini graph | Mini graph expanded |
|---|---|

| 
|
Pipeline success and duration charts
Pipeline analytics are available on the CI/CD Analytics page.
Pipeline badges
Pipeline status and test coverage report badges are available and configurable for each project. For information on adding pipeline badges to projects, see Pipeline badges.
Pipelines API
GitLab provides API endpoints to:
- Perform basic functions. For more information, see Pipelines API.
- Maintain pipeline schedules. For more information, see Pipeline schedules API.
- Trigger pipeline runs. For more information, see: